Why this matters: If you can guide LLMs well, you can draft, analyze, and prototype faster without losing accuracy.
Attention Activity: Two Prompts, Two Worlds
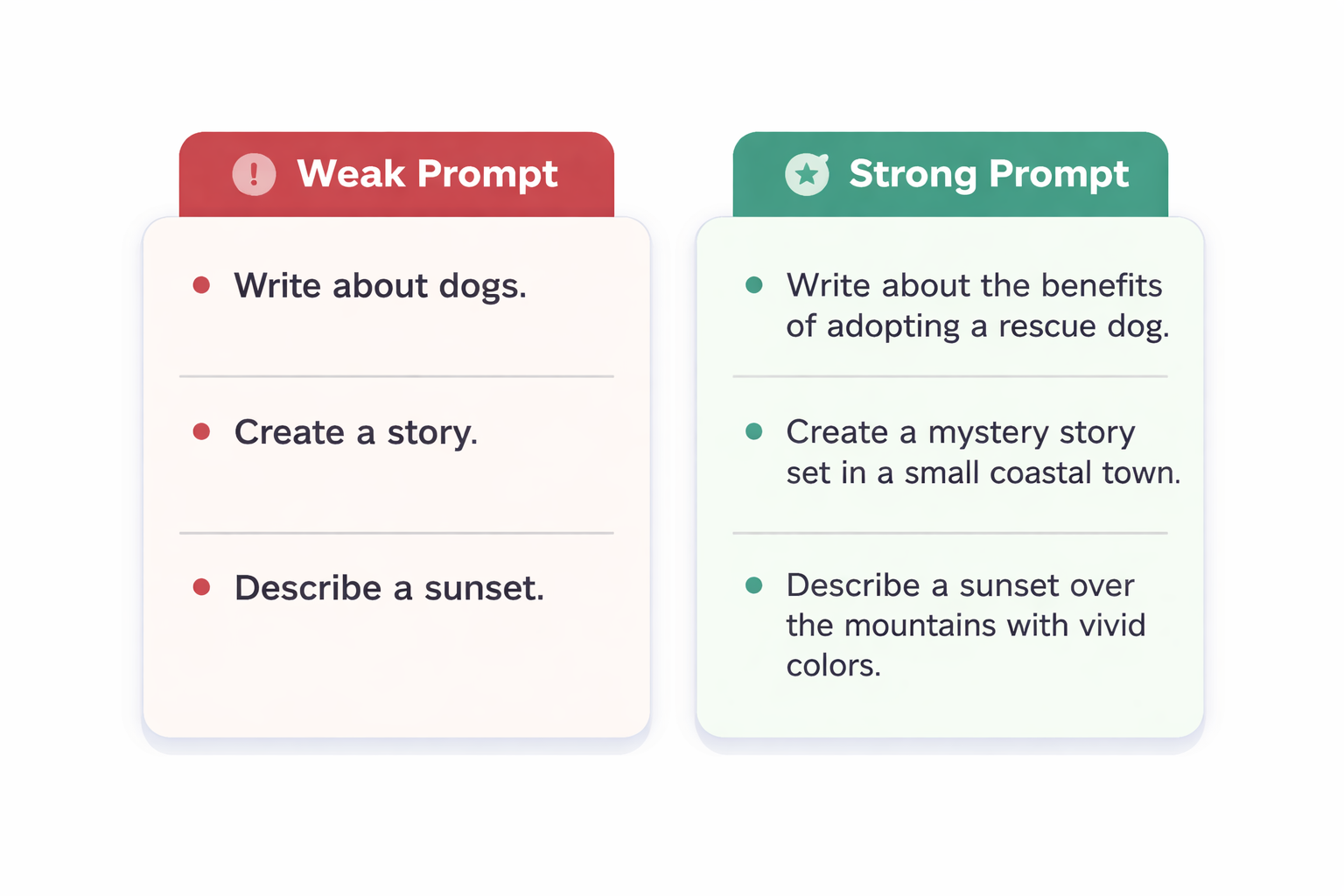
Imagine you ask an AI:
Which prompt is more likely to give you something you can paste straight into a slide deck?

What Is a Large Language Model?
An LLM is a neural network trained on large text datasets to predict the next token in a sequence. With enough training, this simple objective lets the model summarize, translate, and reason over text-like data.
- Tokens are chunks of text (often ~4 characters or a short word).
- Parameters are the model's learned weights.
- Context is the window of tokens the model can see at once.
What LLMs Do Well & Where They Struggle
- Summarizing long text into key ideas.
- Rephrasing or translating while keeping intent.
- Brainstorming options and edge cases quickly.
- May hallucinate — produce confident but false details.
- Doesn't have real-time knowledge unless tools or updates are added.
- Can reflect biases present in training data.
Knowledge Check: What's Really Happening?
When an LLM responds to your prompt, what is it fundamentally doing?
Why Prompt Quality Matters
Because LLMs complete patterns, your prompt defines the pattern. Vague prompts invite generic, less reliable answers. Specific prompts constrain the space of good completions.
"Summarize this."
The model has to guess audience, tone, and length.
"Summarize this for a VP in 3 bullets, each < 15 words, focusing on risks."
You control who it's for, format, and focus.
Knowledge Check: Improving a Prompt
You want the model to draft a customer email apologizing for a delayed shipment. Which revision improves control?
Judging LLM Responses
LLMs sound confident even when wrong, so you need a quick evaluation checklist.
- Factual? Spot-check claims against trusted sources or internal systems.
- Complete? Does it answer all parts of your prompt?
- Safe? Watch for confidential data, biased language, or unsafe suggestions.
When in doubt, ask the model to show sources or to explain its reasoning, then verify externally.
Key Takeaways
- LLMs predict tokens based on learned patterns; they don't "know" facts like a database.
- Clear prompts specify audience, format, and constraints, which improves usefulness and reliability.
- You are accountable for checking factual accuracy, completeness, and safety before using outputs.
- Short internal checklists and examples help teams use LLMs consistently and responsibly.
Up next: a short assessment to apply these ideas in realistic scenarios.
Assessment: Applying LLM Basics
You'll answer 4 scenario-based questions. Each has one best answer. Aim for at least 80% to earn your completion certificate.
Questions focus on selecting better prompts, spotting hidden risks, and choosing reasonable evaluation steps.
Loading question 1...
Loading question 2...
Loading question 3...
Loading question 4...
Assessment Results
Your final score: